
Meet your AI App and Agent Factory
It's never been easier to build, optimize, and govern AI apps and agents that understand your business context and deliver business impact.
Microsoft Foundry helps teams accelerate innovation with open-source frameworks, the widest model selection on any cloud, RAG on data stored anywhere,
secure MCP tools, and VS Code integration.
Govern the entire AI lifecycle with end-to-end observability, evaluations, and security controls.
Stop wrestling with disconnected AI tools.
Find out why Microsoft Foundry is used by developers at more than 80,000 organizations, including 80% of Fortune 500 companies.
👉 Get started in minutes
Code your personal credit card to meet your needs. With Klutch, your card becomes an API-powered dev environment, offering direct access to financial data, unlimited virtual cards, and full programmatic control over spending rules, automations, and real-time transaction behavior. Check out what you can do with a Klutchcard.
Most systems don't need global message ordering.
They need something simpler and more useful: events must be handled in order per aggregate.
Per OrderId, per InvoiceId, per CustomerId, or whatever your aggregate boundary is.
You can make this as broad or as narrow as you need.
This starts as an eventing problem, but if you follow the requirements to their logical conclusion, you'll end up with a workflow. And that workflow has a name: a saga.
Domain Events Feel Like the Clean Solution
Domain events are attractive because they come from first principles:
- An aggregate changes state
- It emits events describing what happened
- Handlers react and do useful work
You also get a nice mental model:
State change → Event → Reaction
A typical example:
OrderPlacedPaymentCapturedOrderShipped
But there's a catch.
Domain events are brittle when you try to use them for integration.
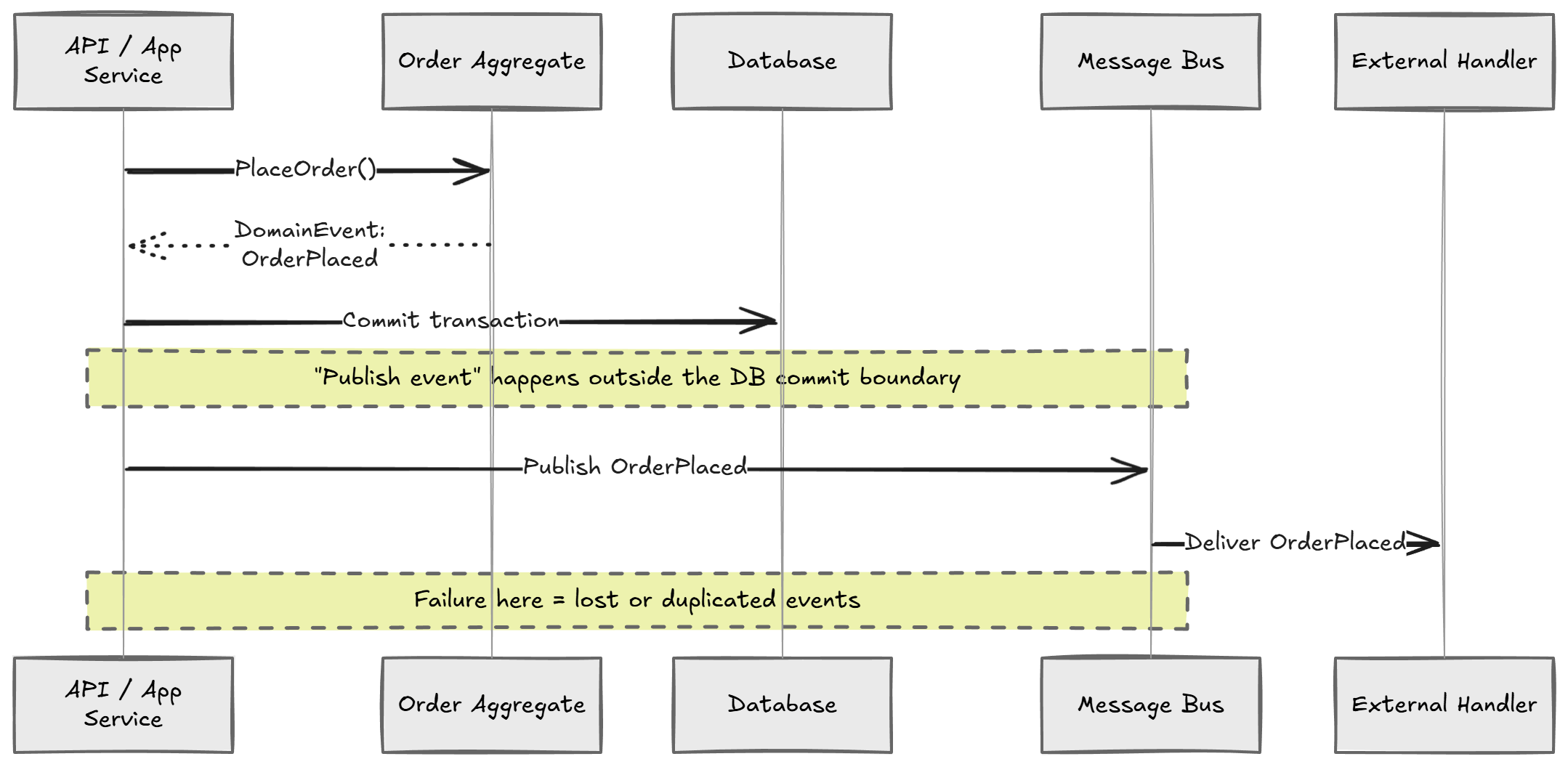
If you publish directly from your transaction, you're coupling business correctness to an unreliable side effect:
- The transaction succeeds but publishing fails
- Publishing succeeds but the transaction rolls back
- Consumers process duplicates
- Retries cause reordering
So we keep the model, but harden the delivery.
The Outbox Makes Publishing Reliable (but not ordered)
With an Outbox, we store outgoing events in the same transaction as the aggregate update.
Then a background publisher reads the Outbox and pushes events to a queue.
This fixes the reliability problem:
- If the transaction commits, the event is persisted
- If the publisher crashes, it can resume later
- We can retry safely

Now we've made event publishing reliable.
But we haven't made event handling ordered.
Competing consumers Are Great, Until Order Matters
The moment events hit a queue, we usually scale with the simplest lever: competing consumers.
Multiple instances consume from the same queue to increase throughput.
That works… until ordering matters.
Two events for the same OrderId can be processed at the same time:
- Consumer A receives
PaymentCaptured - Consumer B receives
OrderPlaced - Side effects run out of order
Even if the events were published in order, retries and redelivery can scramble processing order.
And now you have a subtle bug that only appears under load.
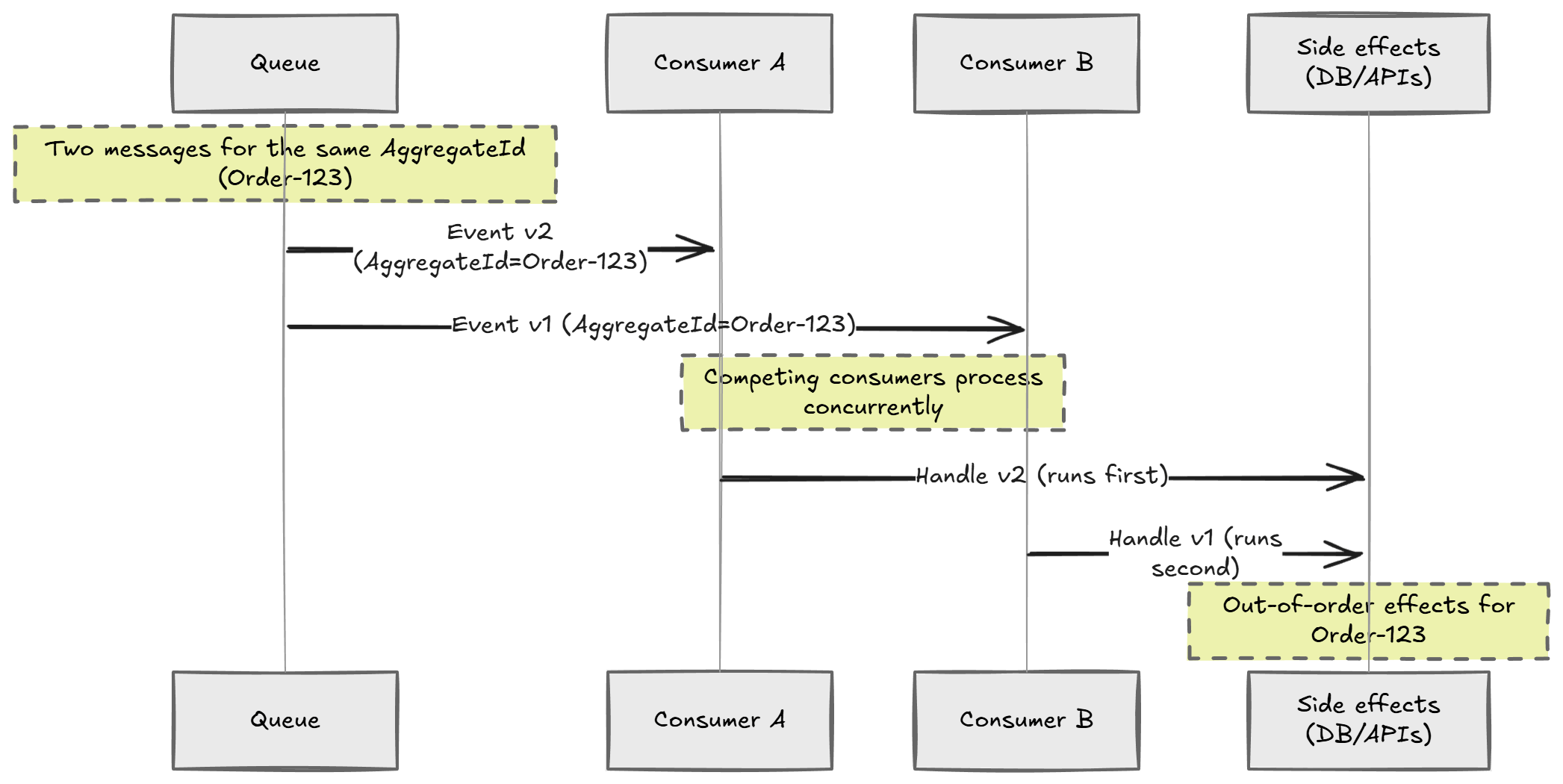
That's the key realization: queues scale work. They don't preserve your invariants.
What We Really Want is Per-Aggregate Ordering
You don't need one ordered line for everything.
You need many independent ordered lines, one per aggregate.
That usually holds true because:
- Aggregates already define consistency boundaries
- Events are naturally produced in order (v1, v2, v3…)
- The "correct" order is the aggregate's own timeline
If we could guarantee that only one handler processes events for a given aggregate at a time, most of the problem disappears.
The most direct solution is also the simplest: use a single consumer for the whole stream.
That enforces ordering, assuming events are published in order.
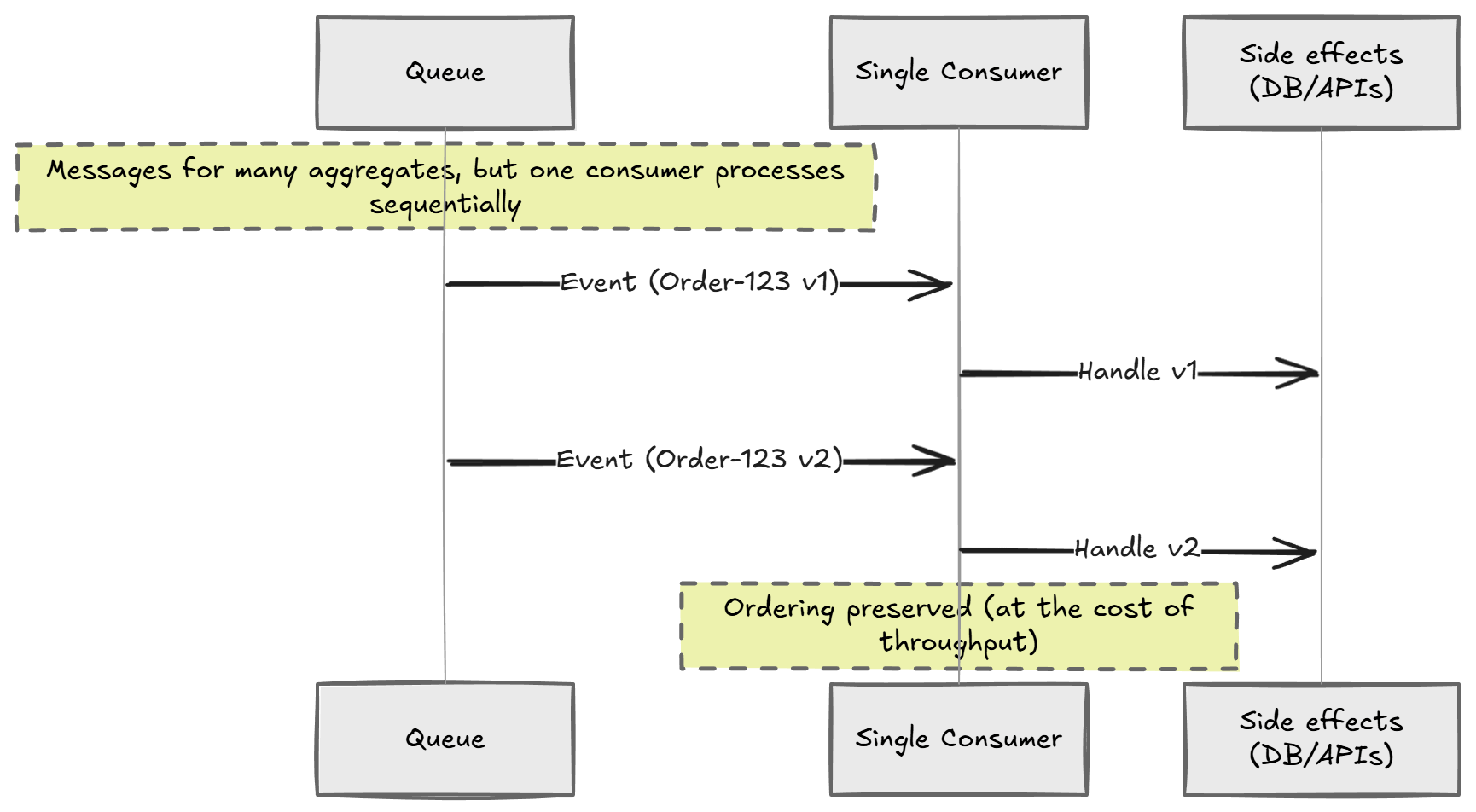
But it has an obvious drawback.
A Single Consumer Solves Ordering But Limits Scale
One consumer means:
- Throughput ceiling (one worker)
- Latency spikes under load
- Scaling becomes vertical, not horizontal
Even if your events are lightweight, you're artificially bottlenecking the system.
So we want:
- Per-aggregate ordering
- Horizontal scaling
- Reliability (Outbox still stays)
This is where teams often "invent" the next step.
Publish the Next Message From the Handler
If competing consumers break ordering, one natural idea is:
Don't let the queue decide what's next, we decide.
Instead of dumping all events into the queue and letting consumers race, we move to a chained approach:
- Handle one message for an aggregate
- When done, publish the next message to be handled
Now, the system processes a single message at a time per aggregate.
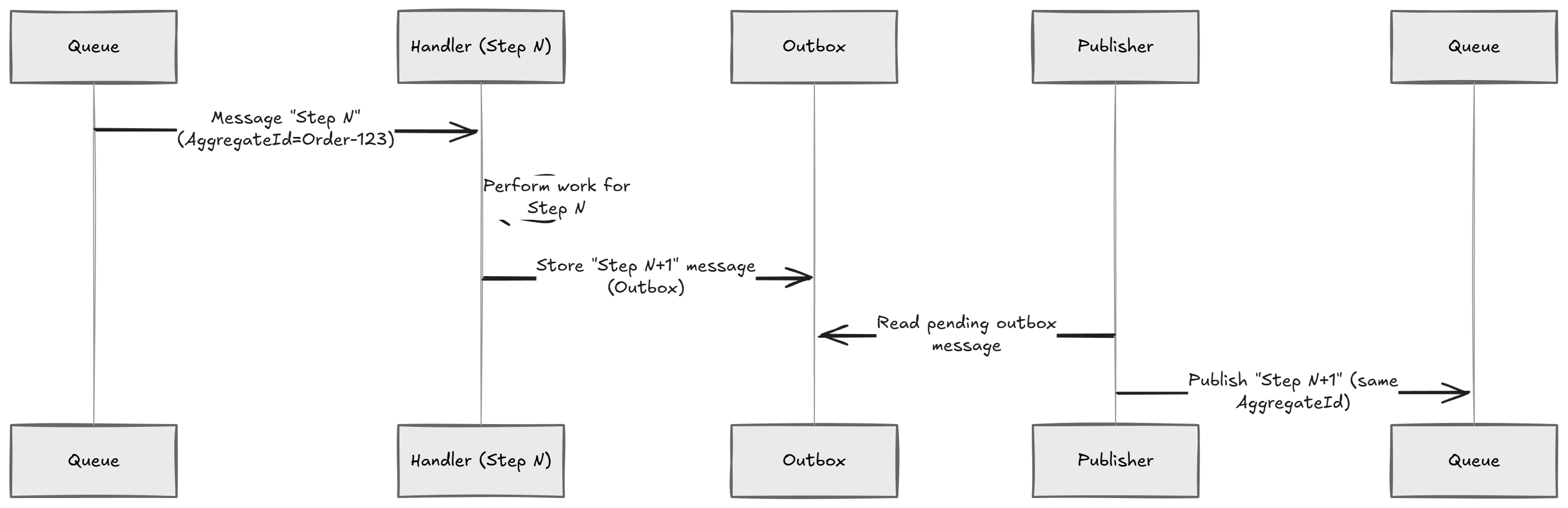
This is the key moment:
You've stopped building "event handlers".
You've started building a workflow.
And that workflow is… a saga.
Congratulations, You Built a Choreographed Saga
A choreographed saga is a workflow where:
- Each step reacts to an event
- Performs work
- Emits the next event to trigger the next step
There isn't a single central coordinator.
Instead, we have a chain of events: "when X happens, do Y, then publish Z".
This pattern naturally fits your new requirement:
- Per-aggregate ordering is preserved (the chain is sequential)
- You can scale across aggregates (many chains in flight)
- Each step is isolated and retryable
It also forces a useful discipline:
- "What's the next step?" becomes explicit
- Boundaries between steps become clearer
- You can observe the workflow as a sequence
But choreography has a limitation: control is distributed, so tracking progress and handling exceptions can get messy.
So we take the final step.
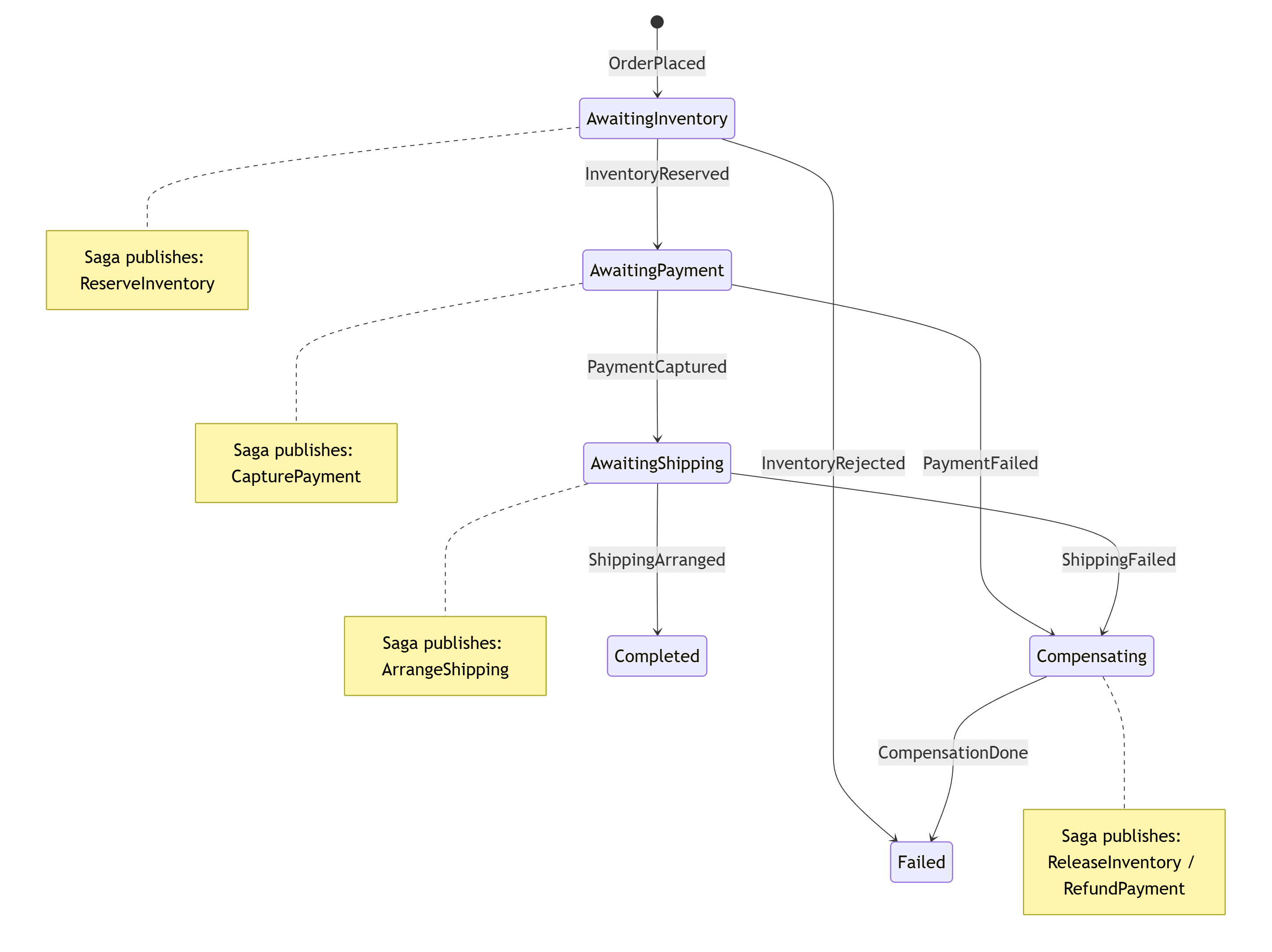
If You Want Control, Introduce a State Machine Saga
When the workflow becomes important, you often want:
- A single place that knows the current state
- Visibility into progress ("where are we stuck?")
- Explicit timeouts and retries
- Compensating actions when something fails
That's when you move from choreography to orchestration via a state machine saga:
- The saga holds the workflow state
- Events drive transitions
- The saga decides what message to publish next
- You gain control and observability
This doesn't replace the Outbox, by the way.
You still want reliable publishing.
You've just made the workflow explicit.
Broker Support Helps with Ordering, not Correctness
It's worth calling out that you don't always have to build this yourself.
Many popular message brokers provide technical primitives for ordered processing per key (your aggregate ID):
- Amazon SQS FIFO message groups (per key)
- Azure Service Bus sessions (per key)
- Kafka Partitions in a log (key → partition → ordered stream)
- RabbitMQ "single active consumer" style semantics (per queue)
These features can eliminate the most common failure mode of competing consumers: concurrent handling of messages for the same aggregate.
But even with perfect per-aggregate ordering, you still need patterns around it to keep the system correct:
- Outbox to publish reliably (ordering is useless if events are lost)
- Idempotent consumers / Inbox because retries and duplicates still happen
- Consistency boundaries (what's safe to do inside the transaction vs outside)
- Timeouts + compensation when the "ordered sequence" is actually a business workflow that can partially fail
So broker-level ordering is a great foundation. It reduces accidental complexity. It just doesn't remove the need to model long-running work explicitly when the business demands it.
Takeaway
If you follow the problem from first principles:
- Aggregates define the boundary where ordering matters
- The Outbox makes event publishing reliable
- Competing consumers break per-aggregate order
- A single consumer restores order but caps throughput
- Publishing "the next message" creates sequential progress per aggregate
- That sequential progress is a saga (choreographed first, state machine when you need control)
So you didn't reinvent something by accident.
You discovered that "ordered handling per aggregate at scale" is not a queue feature.
It's a workflow. And sagas are how we model workflows in distributed systems.
Once you see it that way, you stop fighting queues for ordering guarantees.
You design the workflow the business actually needs.
Hope this was helpful!


