
Secure your "vibe-coded" app before a high traffic spike breaks it. Leverage Redis Cloud for ultra-low latency, application-layer rate limiting to block brute-force attempts and mitigate DDoS surges. Explore Redis Cloud and start for free today to keep your backend protected and resilient under pressure. Use the code MILAN100 for $100 in free credits.
Most cloud migration plans stall in the planning phase. Microsoft's new Azure Copilot Migration Agent generates one automatically from your VMware inventory, compares lift-and-shift against modernization, and hands landing zone templates to GitHub Copilot. It's one of six Copilot agents now covering the full Azure ops cycle. The free Introduction to Azure Copilot Agents module on MS Learn walks through each. Check it out. Start the free module.
Every system I've worked on eventually grows an endpoint that takes minutes to finish (or longer). A report that aggregates years of data. A bulk import. A workflow that fans out to three external services and a database before it can answer.
You end up with two problems at once. Your users sit on a spinner for several minutes, and your API holds that request open the entire time - burning a thread, a connection, and a slot in your concurrency budget. A small traffic spike on that one endpoint could potentially take the rest of the API down with it.
I want to walk through the progression I use to fix this. It's the same path the diagram below traces, from "the request just blocks" to a fully decoupled, queue-backed worker pool - the shape I usually call an async API.
Depending on your requirements, you might stop at any point along the way - but I want to make sure you understand the full path and the trade-offs at each step.
Step 0: The Naive Version
A user sends a request. The application server does the work. The work takes five minutes. The connection stays open the whole time.
There is nothing wrong with this approach - it's just paying for correctness with availability. The user experience is bad, and the blast radius is large: every long request you accept is a request you can't accept somewhere else.
The first realization you need to internalize is that the response time and the work duration don't have to be the same thing.

Step 1: Accept the Work, Don't Do It
The first move is to stop doing the work inside the request.
I add a jobs table that represents the work I intend to do. The API endpoint now does three things:
- Validate the request.
- Insert a row into
jobswith statusPending. - Return
202 Acceptedwith a job ID.
A background processor running inside the same API picks up Pending rows and works through them.
The client either polls a GET /jobs/{id} endpoint or - better - I push updates via SignalR,
Server-Sent Events, or email when the job is done.
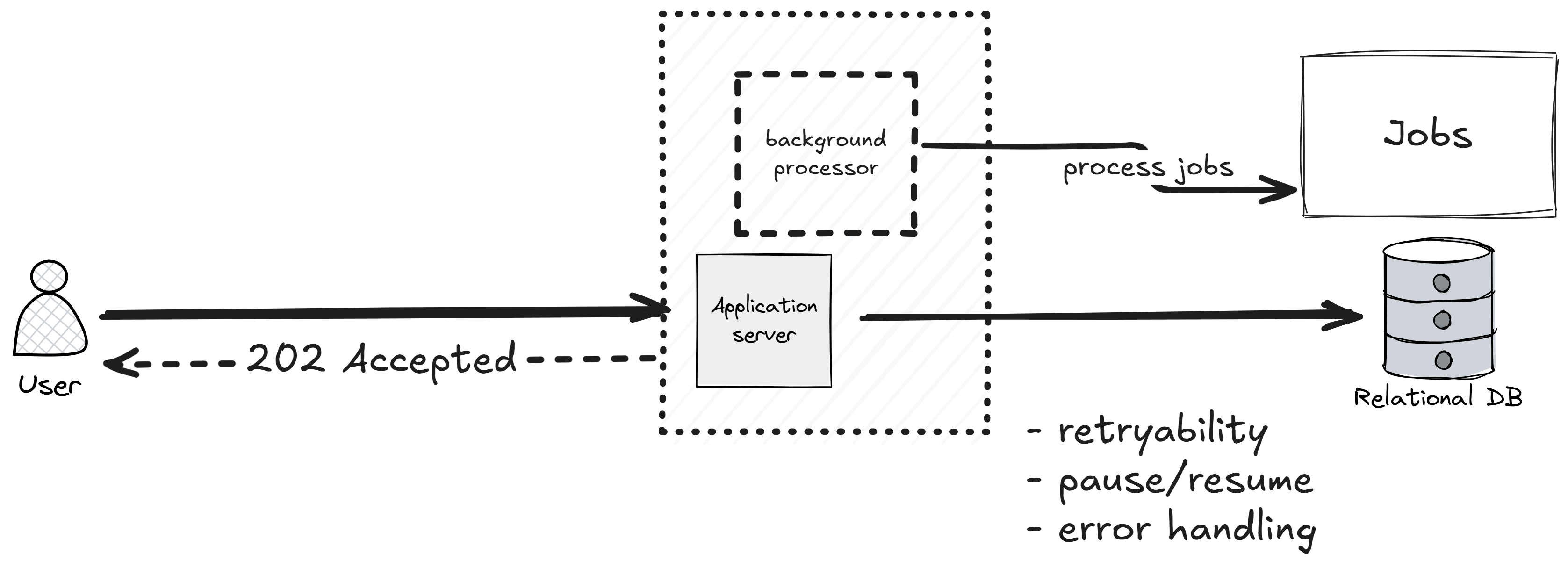
This already buys you a lot. The endpoint returns in milliseconds, the user gets a job ID they can track, and a spike of incoming requests just becomes a spike of rows in a table. That table is cheap to write to.
But there's a ceiling here, and it's easy to hit.
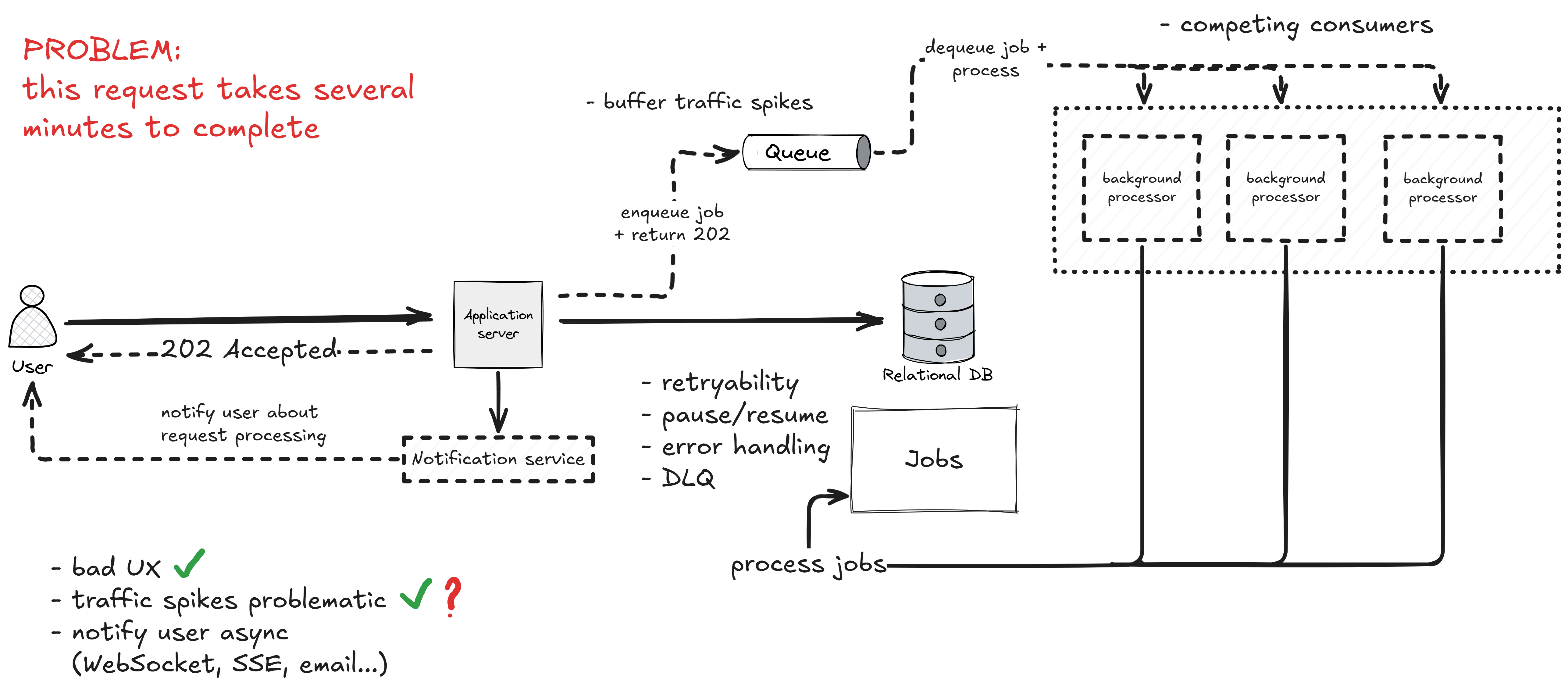
Step 2: Decouple the Worker From the API
The background processor in Step 1 still lives inside your API process. It competes for the same CPU, memory, and connection pool as your real endpoints. If processing gets heavy or slow, your API starts feeling it - the very thing you were trying to avoid.
The fix is to pull the background processor out into its own deployable, and put a queue between the two.
The API now publishes a message to the queue (and optionally writes the job row for tracking). A pool of background workers consumes from the queue and does the actual work - the same shape I covered in event-driven architecture with RabbitMQ. This is the competing consumers pattern, and it gives you something the previous step couldn't: independent scaling.
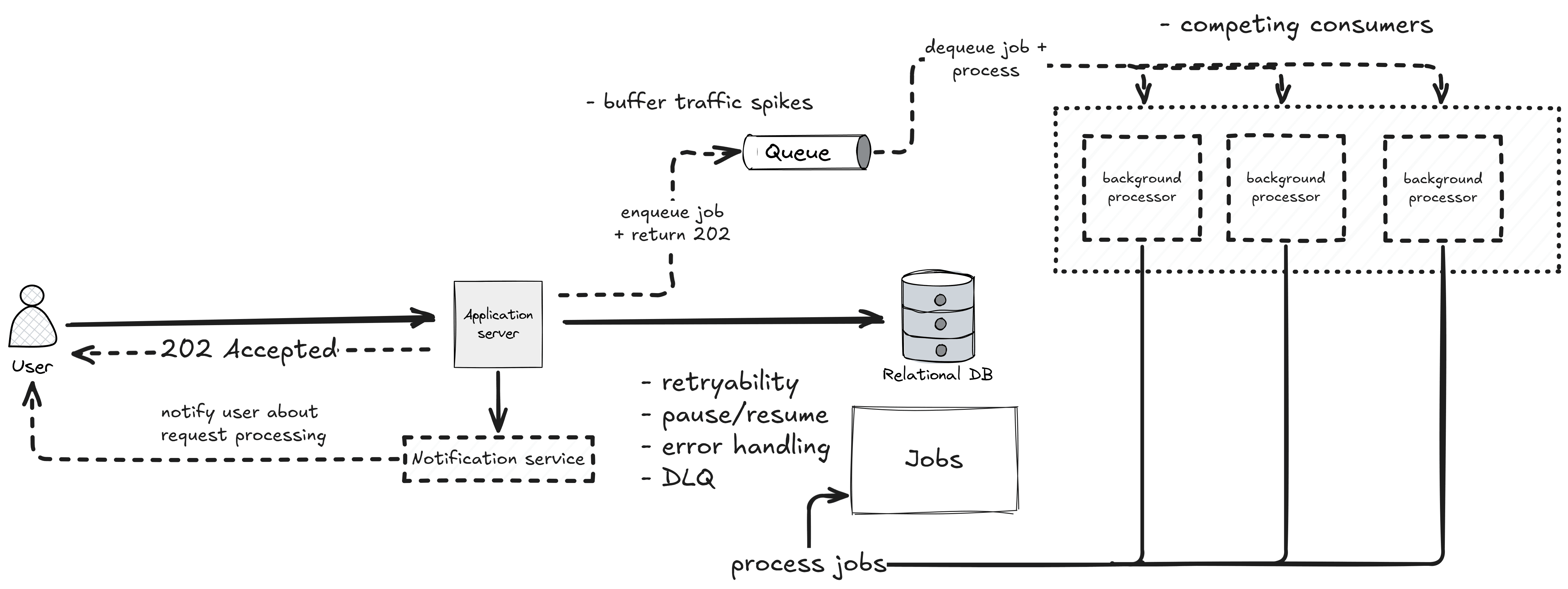
Three things change once you cross this line:
- The queue absorbs spikes. Your API can keep accepting work at a constant rate while the workers drain at their own pace.
- You scale workers separately from the API. More throughput on background jobs doesn't mean more API instances.
- Failures become normal. A worker crash is just a message that goes back on the queue, not a 500 to your user.
You also get retryability, pause/resume, structured error handling, and a dead-letter queue for poison messages - effectively for free, because the queue infrastructure already provides them.
What This Costs You
I'd be lying if I said this was a free upgrade.
You're now running a queue, a worker fleet, and a notification path. That's more moving parts to deploy, monitor, and alert on. Your "is this done yet?" semantics are no longer obvious from the HTTP response - the client has to ask, or you have to tell them. And every job needs to be idempotent, because at-least-once delivery means your workers will see duplicates.
If you only have one slow endpoint and modest traffic, this is overkill. A simple "fire-and-forget with status polling" inside the same process is fine. Don't reach for a queue until the pain justifies it.
When I'd Use a Cloud Service Instead
You don't always need to assemble this from parts. A few alternatives I would consider:
- AWS SQS + Lambda or Azure Service Bus + Azure Functions when I want the worker pool to scale to zero and I don't want to manage hosts.
- Azure Durable Functions or AWS Step Functions when the work is a multi-step workflow with timers, retries, and human approvals. Orchestration is what they're good at.
- Temporal when the workflow is long-lived (hours, days) and I need first-class durable execution, versioning, and visibility across runs.
The trade-off is the usual one: less operational work, more vendor coupling, and a pricing model you need to model carefully when throughput grows.
Summary
The progression is simple, and it generalizes:
- Don't do slow work inside the request. Accept it, persist it, return
202. - Don't run workers inside the API. Put a queue in between and scale the two sides independently.
- Tell the user when it's done. Polling is fine, push is better.
This isn't a microservices argument. It's a separation between accepting work and doing work - two concerns that have very different scaling profiles and very different failure modes.
If you want the full implementation walkthrough, the video version is here.
Thanks for reading.
And stay awesome!


