

BoldSign API & SDKs for Developers – Add contract signing to your app in minutes with our .NET SDK. Fully embed sending and signing, control branding and emails, get transparent pricing, and start testing instantly in our free sandbox. Trusted by 40K+ businesses and recognized as the #1 developer-choice e-signature API.
MongoDB.local NYC September 17. AI is breaking the old rules. Your database has to keep up. MongoDB wasn't retrofitted for AI; it was born for it, handling the messy, dynamic data that AI thrives on. Join MongoDB.local NYC on Sept 17 at the Javits Center for talks, demos, hands-on labs, and networking. Unlock new possibilities for your data in the age of AI. Register here and use code SOCIAL50 to save 50%.
I implemented full-text search on my static website using Lunr.js. It works great for exact matches or phrases, but it doesn't understand meaning. Someone searches for "modular monolith" and finds posts that contain these phrases. But when they search for "database performance issues," they might miss my articles about query optimization and index tuning, even though that's exactly what they need.
Amazon S3 is now also a vector database, and it's 90% cheaper (according to the announcement) than the alternatives.
For those of us running static sites or simple web apps, it means we can finally add semantic search without the operational overhead of running a vector database like Pinecone, Weaviate, or Qdrant.
Instead, we can just use S3 buckets that understand vectors.
I'm adding it alongside my existing full-text search implementation, and the whole thing took an afternoon to build.
How Semantic Search Works
The entire semantic search flow is straightforward:

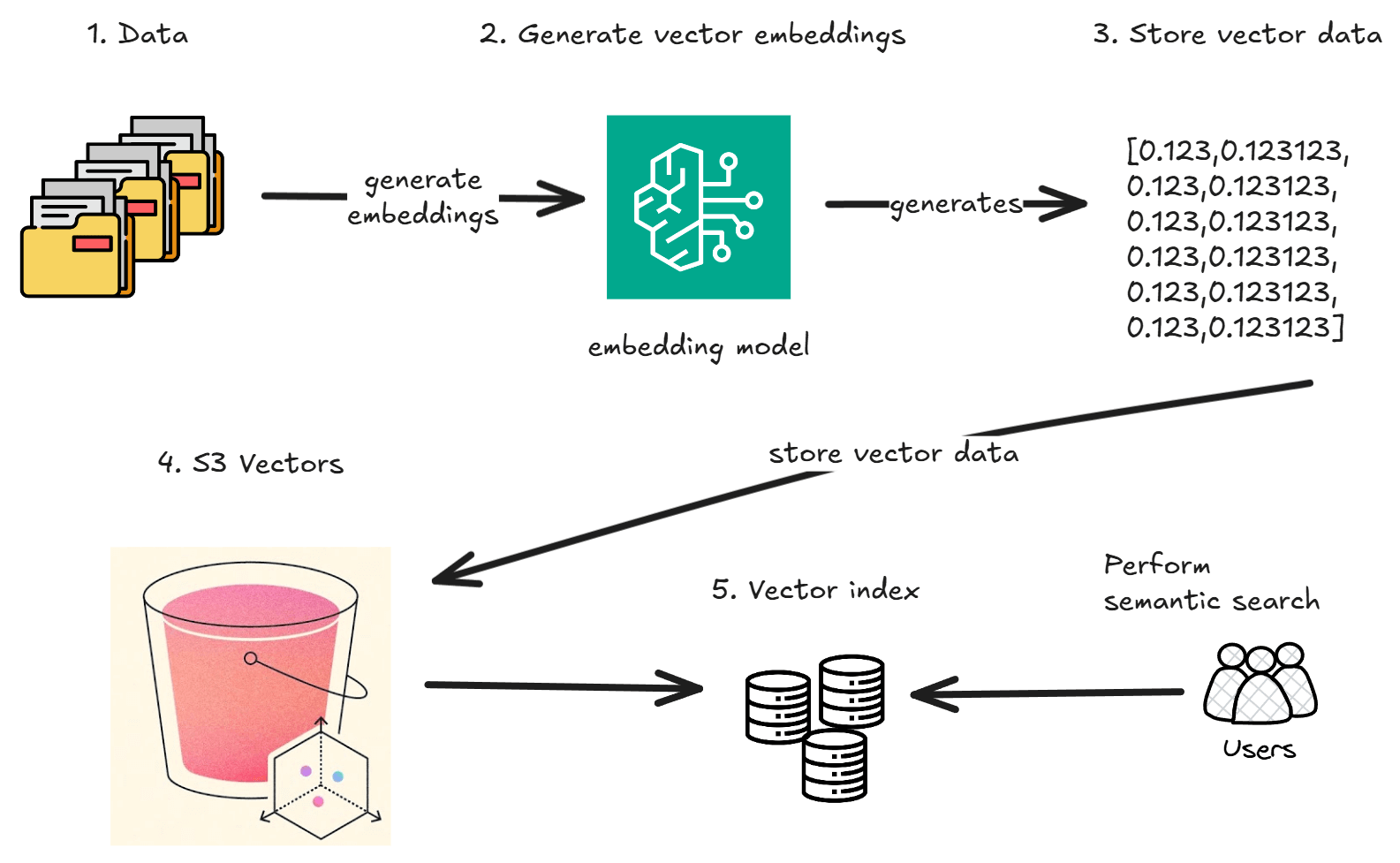
You have to start with some data. In my case, this data comes from the articles I've written over the years.
Then we need an embedding model. Amazon Bedrock offers many to choose from. You use an embedding model to convert text into vectors. Vectors are numerical representations of your data that capture semantic meaning.
Finally, we store these vectors in an S3 Vector Bucket, a new type of S3 bucket designed specifically for vector storage and search. When someone searches, we convert their query into a vector and find the closest matches in the bucket.
If you want to understand the fundamentals, I wrote an article explaining what vector search is.
Generating Embeddings with Semantic Kernel
Microsoft's Semantic Kernel makes working with Bedrock surprisingly clean.
We'll need to install a few NuGet packages:
# Semantic kernel packages
Install-Package Microsoft.SemanticKernel
Install-Package Microsoft.SemanticKernel.Connectors.Amazon
# AWS SDK for Bedrock
Install-Package AWSSDK.BedrockRuntime
We have to configure the embedding generator in our application.
Here we can specify which model to use for generating embeddings.
I'll use the Amazon Titan embedding model (amazon.titan-embed-text-v2:0) which produces 1024-dimensional vectors.
builder.Services.AddBedrockEmbeddingGenerator("amazon.titan-embed-text-v2:0");
builder.Services.AddTransient(sp =>
{
return new Kernel(sp);
});
And then we can use the IEmbeddingGenerator abstraction to generate embeddings:
var kernel = app.Services.GetRequiredService<Kernel>();
var embeddingGenerator = kernel.Services
.GetRequiredService<IEmbeddingGenerator<string, Embedding<float>>>();
var articleContent = await blogService.GetBlogContentAsync(articleUrl);
Embedding<float> embedding = await embeddingGenerator.GenerateAsync(articleContent);
embeddings.Add((articleUrl, embedding.Vector.ToArray()));
The number of dimensions varies depending on the embedding model you choose. You can find more information about that in the documentation for your specific model.
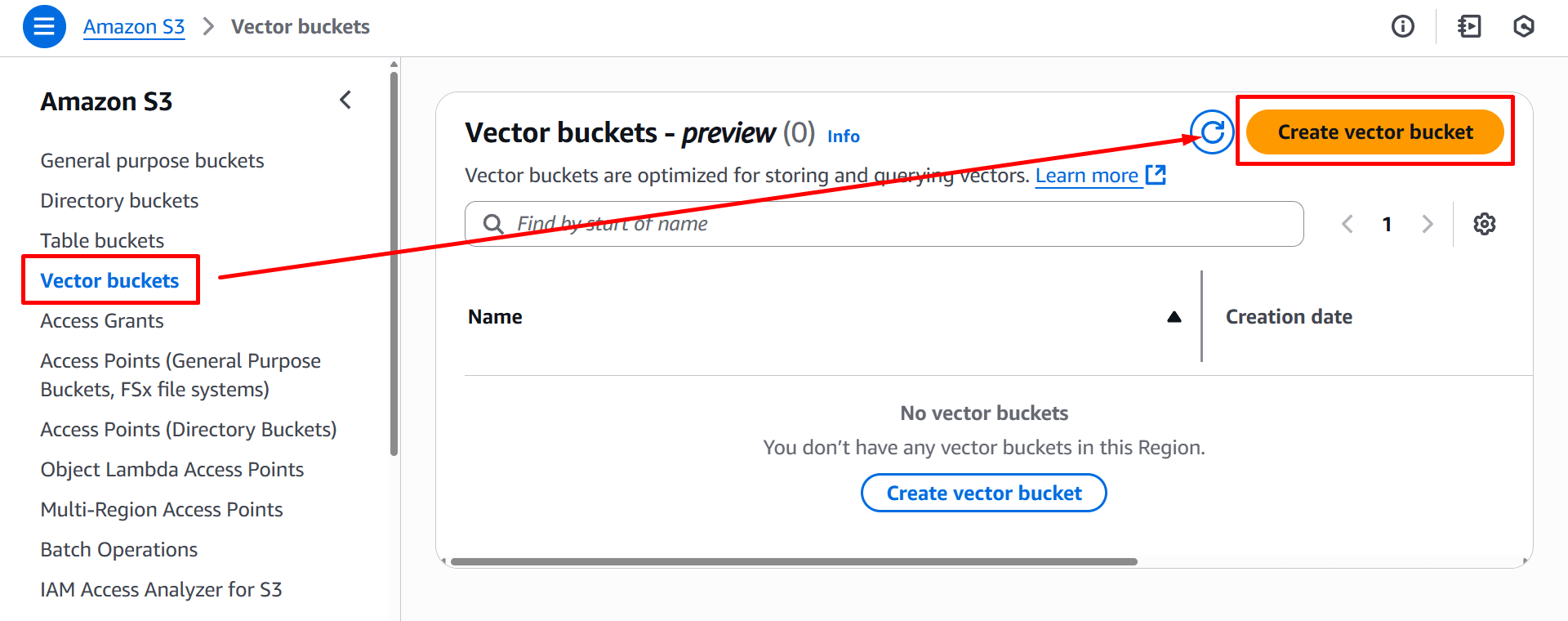
Creating Your S3 Vector Bucket
S3 Vectors uses an entirely new bucket type, not a feature you enable on existing buckets. They're a fundamentally different storage system optimized for vector operations. Creating one feels familiar if you've used S3 before:

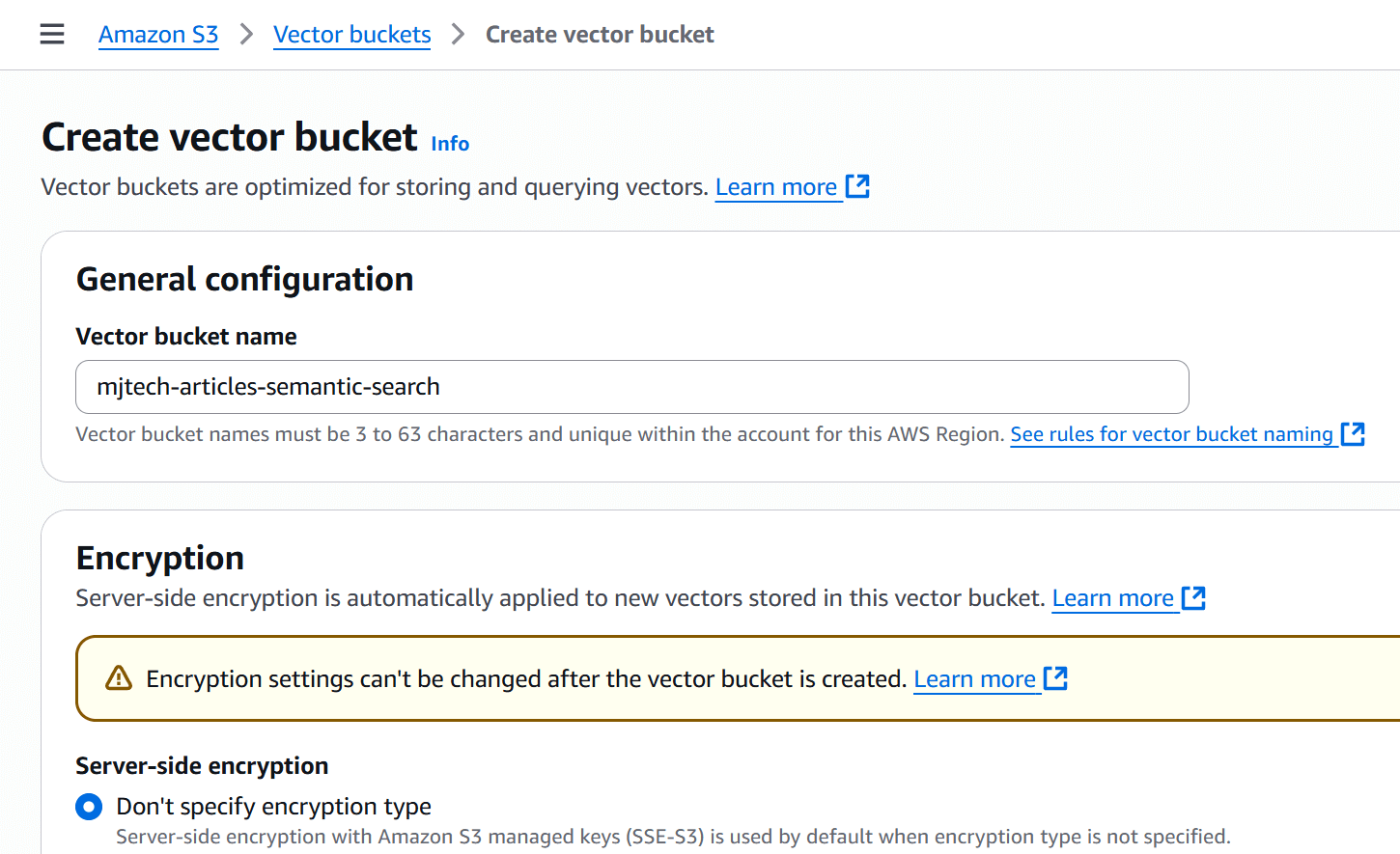
Pick a unique name for your vector bucket:

And finally, you can create a vector index for your bucket. You get to choose the number of dimensions in each vector. This is dictated by the embedding model you use. All vectors within a vector index should use the same embedding model. Otherwise, you won't get the correct results when searching. You also have to choose the distance metric (e.g., cosine similarity, Euclidean distance) for your vector index. I went with cosine similarity, which is a common choice for text embeddings. The additional settings let you configure non-filterable metadata. By default, all metadata is filterable.

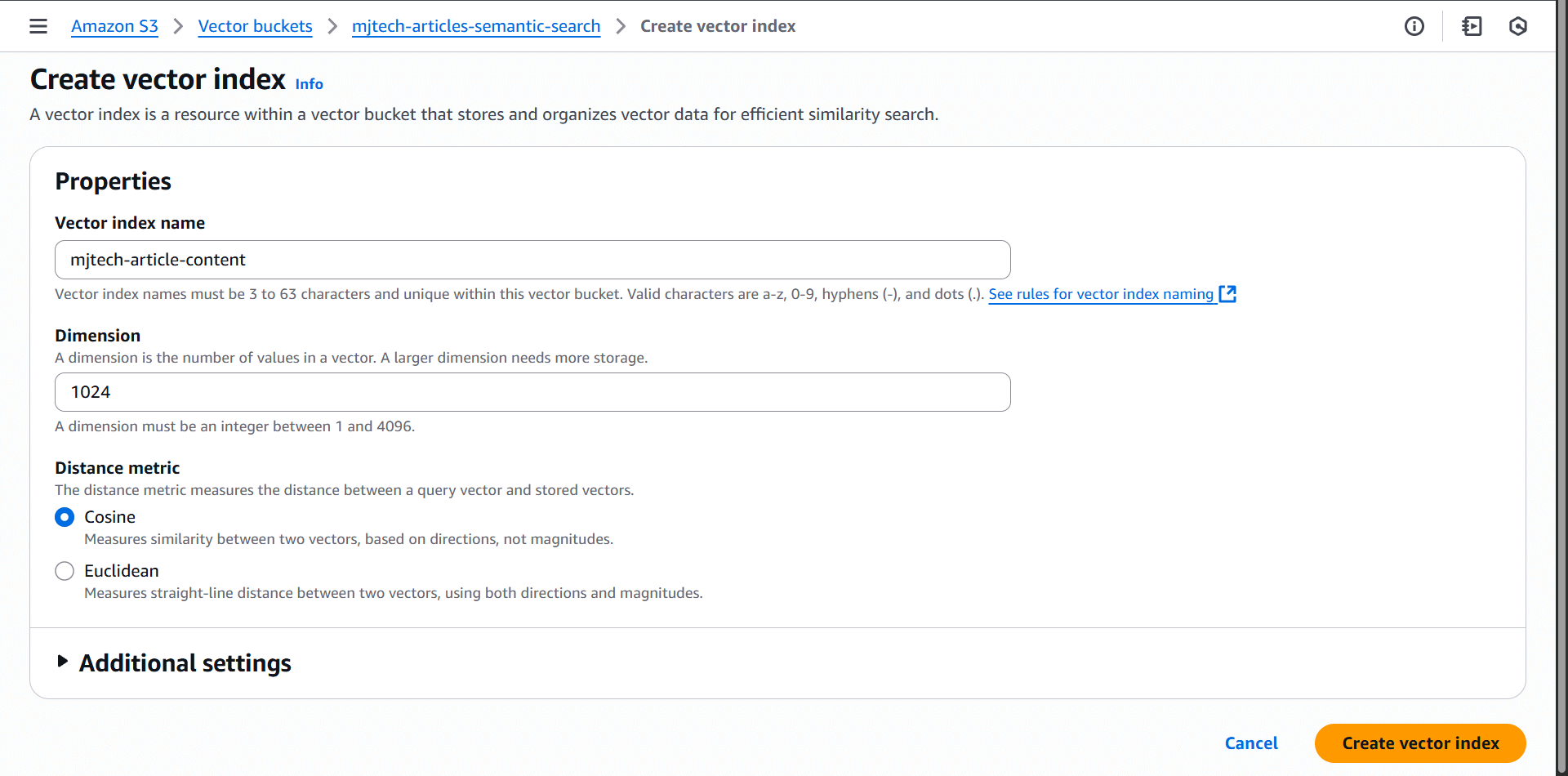
The UI is not polished at all, and you can't do much else. I expect this will improve over time, but for now, everything else is done via the SDK or CLI. There are certain limitations to be aware of, you can check out the docs here.
Storing Vectors with Metadata
Now that we have our vector index, we can start storing vector embeddings with metadata. Metadata is interesting because it enables filtered searches. Want to search only recent posts? Posts in a specific category? The metadata makes it possible.
Here's how you can store vectors:
public async Task IndexBlogPost(BlogPost post)
{
List<float> embedding = await GenerateEmbedding(post.Content);
await s3VectorsClient.PutVectorsAsync(new PutVectorsRequest
{
VectorBucketName = "mjtech-articles-semantic-search",
IndexName = "mjtech-article-content",
Vectors = new List<Vector>
{
new PutInputVector
{
Key = post.Slug,
Data = new VectorData
{
Float32 = embedding
},
Metadata = new Document(new Dictionary<string, Document>
{
["title"] = post.Title,
["date"] = post.PublishedDate.ToString("yyyy-MM-dd"),
["category"] = post.Category,
["url"] = $"/posts/{post.Slug}"
})
}
}
});
}
But if you're indexing your entire blog archive, doing it one post at a time is costly. You can batch together multiple posts and index them in a single API call. The SDK makes it easy to do this by accepting a list of vectors.
Querying Vector Indexes
When someone searches your site, you convert their query into a vector and find the closest matches.
Here's how you can implement semantic search:
public async Task<List<SearchResult>> SemanticSearch(
string query,
int topK = 10)
{
// Convert search query to vector (use same model as vectors!)
List<float> queryEmbedding = await GenerateEmbedding(query);
var request = new QueryVectorsRequest
{
VectorBucketName = "mjtech-articles-semantic-search",
IndexName = "mjtech-article-content",
QueryVector = new VectorData
{
Float32 = queryEmbedding
},
TopK = topK,
ReturnMetadata = true,
ReturnDistance = true
};
QueryVectorsResponse response = await s3VectorsClient.QueryVectorsAsync(request);
return response.Vectors.Select(v => new SearchResult
{
Distance = v.Distance,
Title = v.Metadata.AsDictionary()["title"].ToString(),
Url = v.Metadata.AsDictionary()["url"].ToString(),
Category = v.Metadata.AsDictionary()["category"].ToString()
}).ToList();
}
I omitted metadata filtering here, but you can explore the documentation for more details.
Next Steps
Would I migrate from an existing vector database? Probably not if everything's working. The operational overhead would have to justify the switch.
But if you're adding semantic search for the first time, or your vector database bills are getting uncomfortable, S3 Vectors is a viable choice. The setup takes an afternoon, the ongoing maintenance is zero, and your users get search that actually understands what they're looking for.
Don't forget that S3 Vectors is still in preview, so we can expect some changes before general availability.
Here's what I'm planning to do next:
- Automatically update the vector index when I publish a new post. I can do this in my CI/CD pipeline, where I can detect new posts and trigger a re-indexing.
- Expose a search endpoint that uses the new semantic search capabilities. Combine the results with the full-text search results.
- Make sure everything is performant and cost-effective. Acceptable latency is under 500ms.
- Share details about the implementation and any challenges faced. Especially around the costs of using an embedding model and vector storage.
That's all for today.
See you next week.



